I recently had a customer ask several questions about what IOPS and max throughput mean and how they could increase throughput so that their backup restore process in Azure would take less time. In this post we’ll look at how we can estimate our max throughput and IOPS based on VM size and disk configuration. Additionally, we’ll also look at ways to improve performance without increasing costs.
Problem
How can we estimate what our max IOPS and throughput will be in Azure? And how can we increase IOPS and throughput and perhaps even lower our costs at the same time to achieve our max IOPS or throughput goals?
Solution
First, let’s start with some basic definitions. IOPS stands for input/output operations per second. It’s a measure of performance for storage devices that represents how quickly a storage device can read and write data to disk every second
Throughput is a bit different but related to IOPS. Throughput measures the data transfer rate to and from storage devices per second. Throughput is impacted by IOPS and the block size being written to disk and is measured, typically, in MiB/s.
Understanding how IO is throttled to protect both the storage and compute resources is an important concept to understand when dealing with any cloud provider. Cloud providers place IO limits on both storage and VM resources to help protect resources from workloads that would otherwise cause more serious issues if left unchecked.
Each type of VM and storage resource in Azure provides you with Max IOPS and throughput so that users migrating workloads can estimate if that resource type can support a particular workload.
Take the following table on disk speeds in Azure as an example. This table clearly identifies the IOPS and max throuhput you can expect for disk types by size.
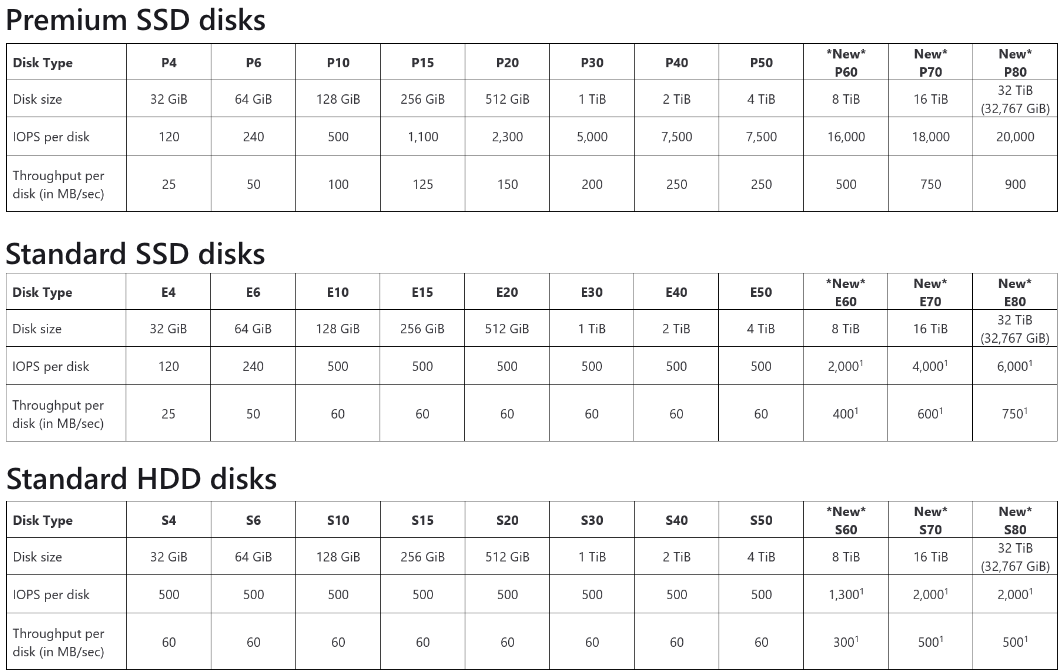
*Above tables taken from here.
The alert reader will notice that HDD disks are actually faster than SSD disk for smaller sized disks, however the thing to note about these smaller disks of both SSD and HDD types are that the performance rate is generally low. Most advanced users will note that the SSD drives in their laptops can do probably 2-5 times the performance of the Premium SSD drives unless you are provisioning disks of more than 8TB. However just remember the disks provisioned in Azure come with SLAs that determine how many copys of the data are written and where that data is written to. This type of redundancy doesn’t come for free in terms of IOPS and throughput.
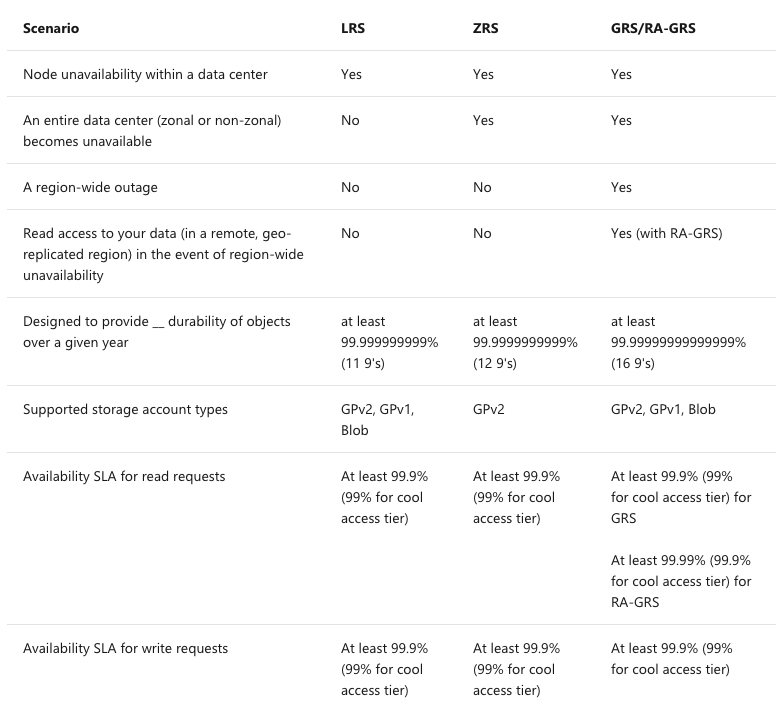
Azure supports several types of storage redundancy. These are:
- LRS: Locally redundant storage
- ZRS: Zone-redundant storage
- GRS: Geo-redundant storage
- RA-GRS: Read access geo-redundant storage
Storage Features by Type
So now that we’ve established that there is lots of goodness that comes with a provisioned disk in Azure let’s look at how we can provision a solution that is cost performant and also provides the necessary level of performance. Obviously the first task on the punch list is understanding the workload you are moving and what its requirements are for CPU, memory and IO. I see many cases where customers provision based on CPU and memory and don’t look at IOPS and throughput until much further down the road when they have unexplained performance problems.
When determining your overall solution ensure that you are looking not only at the CPU and memory of a VM but also its max IOPS and throughput as determined by reviewing the specifications for each VM type
The following is an example of 2 VM type specs taken from the Azure website:
General Purpose and Memory Optimized:
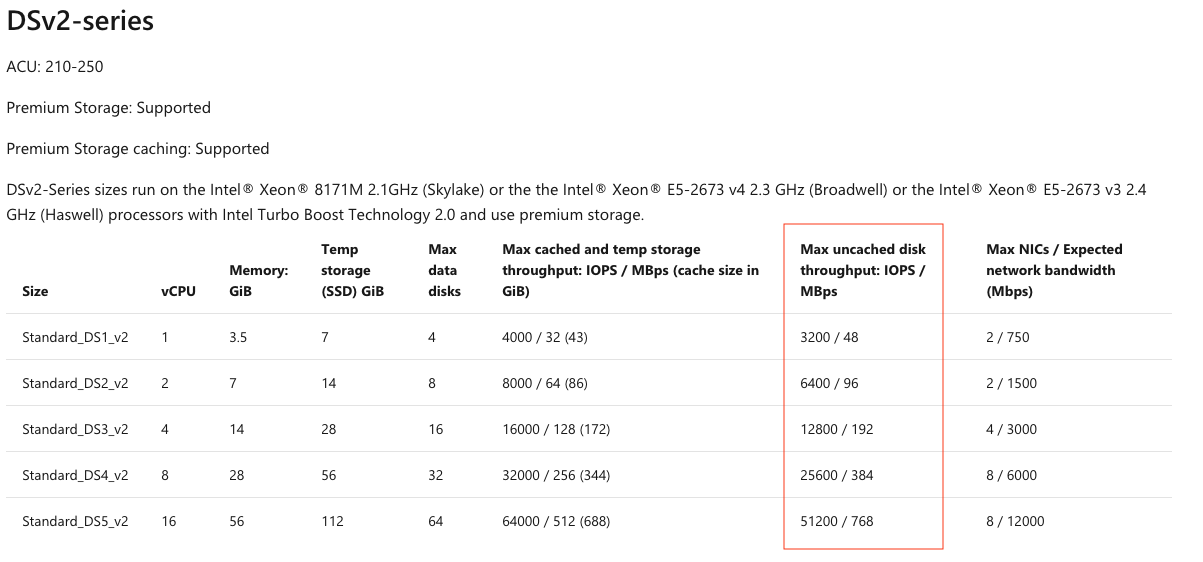
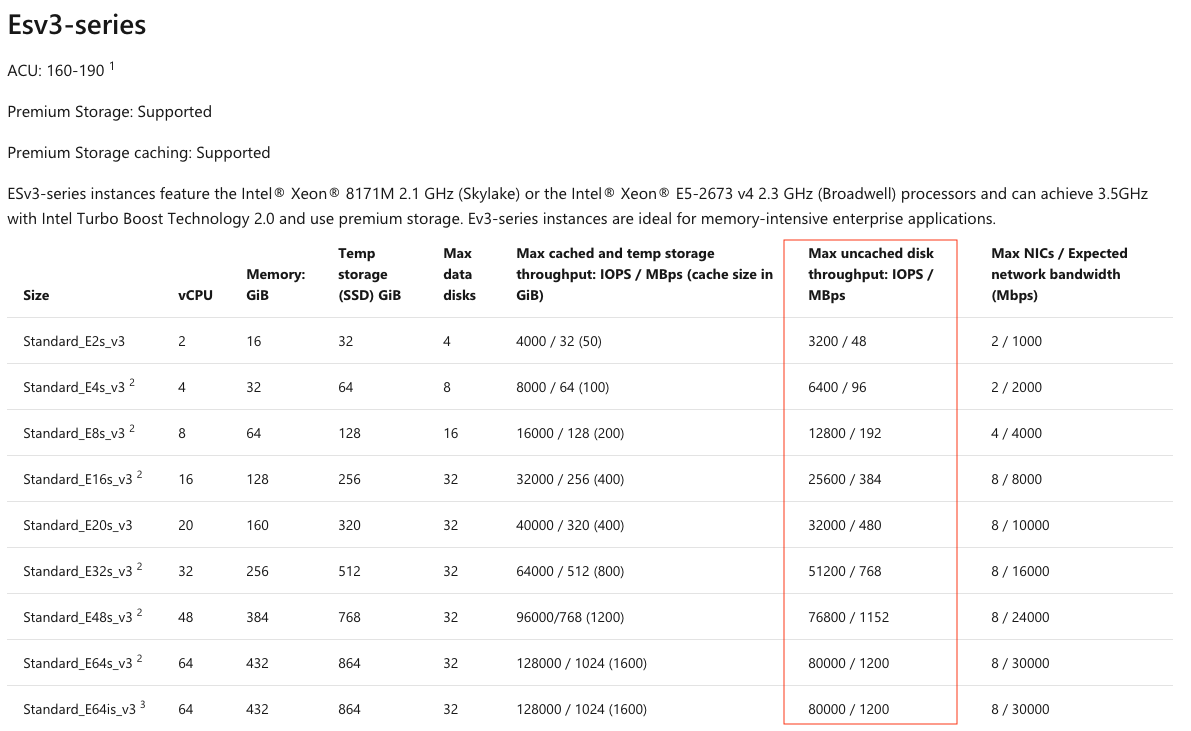
The column highlighted in red provides you with the max IOPS and throughput this VM type is capable of performing. Even if you attach a 32TB Premium SSD capable of 20,000 IOPS and 900MiB/s, if you choose a Standard_DS3v2 (4CPU and 14GB of memory) the max IOPS will be 12,800 and max throughput will be 192MiB/s (the limits of the VM)
Example
Let’s perform some basic benchmarking using Ubuntu 16.04 and an IO tool called fio. In this first scenario let’s look at a DS3v2 with 2 disks attached:
- The first disk will have a Premium SSD (P15) data disk provisioned and attached to it at the /sdc mount point. This is a 256GB disk capable of 1100 IOPS and 125 MiB/s.
- Disk 2 will be a 2TB Premium SSD (P40) capable of 7500 IOPS and 250 MiB/s. This disk will be mounted on /sdd
The following file is used to configure fio for 4 worker threads
>> cat fiowrite.ini
# Contents of fiowrite.ini
############################
[global]
size=30g
direct=1
iodepth=256
ioengine=libaio
bs=512k
[writer1]
rw=randwrite
directory=/sdc/nocache
[writer2]
rw=randwrite
directory=/sdc/nocache
[writer3]
rw=randwrite
directory=/sdc/nocache
[writer4]
rw=randwrite
directory=/sdc/nocache
###### End File ###########
>> fio --runtime 30 fiowrite.ini
writer1: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
writer2: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
writer3: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
writer4: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
fio-3.1
Starting 4 processes
...
Run status group 0 (all jobs):
WRITE: bw=121MiB/s (127MB/s), 28.0MiB/s-30.9MiB/s (30.4MB/s-32.4MB/s), io=3755MiB (3937MB), run=30943-30991msec
Disk stats (read/write):
sdc: ios=0/7513, merge=0/145, ticks=0/29503816, in_queue=26889032, util=90.62%
In this example we are using fio to push throughput (not IOPS) but you can see we got 121 MiB/s which is close to our rate limit for this disk type (125MiB/s). We could probably tweak our fio parameters a bit to get a couple of more MiB but I’ll leave that as an exercise for you, the reader, if you’re interested.
Now let’s look at the P40 disk we mounted on /sdd with a rate limit of 250MiB/s.
>> cat fiowrite.ini
# Contents of fiowrite.ini
############################
[global]
size=30g
direct=1
iodepth=256
ioengine=libaio
bs=512k
[writer1]
rw=randwrite
directory=/sdd/nocache
[writer2]
rw=randwrite
directory=/sdd/nocache
[writer3]
rw=randwrite
directory=/sdd/nocache
[writer4]
rw=randwrite
directory=/sdd/nocache
###### End File ###########
>> fio --runtime 30 fiowrite.ini
writer1: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
writer2: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
writer3: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
weriter4: (g=0): r
w=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
fio-3.1
Starting 4 processes
...
Run status group 0 (all jobs):
WRITE: bw=186MiB/s (195MB/s), 45.4MiB/s-47.9MiB/s (47.6MB/s-50.2MB/s), io=6087MiB (6383MB), run=32215-32750msec
Disk stats (read/write):
sdd: ios=0/12194, merge=0/1119, ticks=0/30530848, in_queue=30570116, util=99.36%
So now we see that we are limited on the P40 disk to ~190MiB/s. This is NOT the limit on the disk but the limit on the VM. We have essentially capped out at 190 MiB/s even though the disk supports up to 250 MiB/s.
Software RAID and Saving Money
So in our quick example we needed to provision at least a P30 Premium SSD to be able to max out our VM’s Max throughput of 192MiB/s, however a P30 is $135/month for a 2 TiB disk whereas a P15 is only $38/month for 256GiB. If we don’t need the full 2 TiB of space but want to increase our Max IOPS and throughput we can use Software RAID (aka mdraid) on Linux. Mdraid will allow us to strip disks together to increase our IOPS, throughput and even redundancy if you want to add additional layers of redundancy to what is already available in Azure.
In this next example I will use 2 256 GiB/s P15 disks in a RAID 0 configuration to create a new Linux device called md0. We’ll mount /dev/md0 on the mountpoint /md0 and run our same test.
Just to recap our disk type quickly a P15 Premium SSD is capable of 1,100 IOPS and 125 MiB/s of throughput.
>> mdadm --create /dev/md0 --level=0 --raid-devices=2 /dev/sdc /dev/sde
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
>> mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Mon Dec 23 22:36:31 2019
Raid Level : raid0
Array Size : 536606720 (511.75 GiB 549.49 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Mon Dec 23 22:36:31 2019
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Chunk Size : 512K
Consistency Policy : none
Name : bastion-vm:0 (local to host bastion-vm)
UUID : 3928e812:2f0096e2:b2b2a398:4e787dc0
Events : 0
Number Major Minor RaidDevice State
0 8 32 0 active sync /dev/sdc
1 8 64 1 active sync /dev/sde
>> parted /dev/md0 mklabel gpt
Information: You may need to update /etc/fstab.
>> parted -a opt /dev/md0 mkpart ext4 0% 100%
Information: You may need to update /etc/fstab.
>> mkfs.ext4 -L datapartition /dev/md0
mke2fs 1.44.1 (24-Mar-2018)
Found a gpt partition table in /dev/md0
Proceed anyway? (y,N) y
Discarding device blocks: done
Creating filesystem with 134151680 4k blocks and 33538048 inodes
Filesystem UUID: da25940a-8c43-4b49-83f4-52a4016563ba
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000
Allocating group tables: done
Writing inode tables: done
Creating journal (262144 blocks): done
Writing superblocks and filesystem accounting information: done
>> mkdir /md0
>> mount /dev/md0 /md0
The previous example created the /dev/md0 device using RAID 0 and mounted in at /md0. If we run our same fio workload against the /md0 device that contains our 2 P15 disks we should see the performance of the /dev/md0 device allow our VM to now reach the full max bandwidth of 192 MiB/s.
>> cat fiowrite.ini
# Contents of fiowrite.ini
############################
[global]
size=30g
direct=1
iodepth=256
ioengine=libaio
bs=512k
[writer1]
rw=randwrite
directory=/md0/nocache
[writer2]
rw=randwrite
directory=/md0/nocache
[writer3]
rw=randwrite
directory=/md0/nocache
[writer4]
rw=randwrite
directory=/md0/nocache
###### End File ###########
>> fio --runtime 30 fiowrite.ini
writer1: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
writer2: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
writer3: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
writer4: (g=0): rw=randwrite, bs=(R) 512KiB-512KiB, (W) 512KiB-512KiB, (T) 512KiB-512KiB, ioengine=libaio, iodepth=256
fio-3.1
Starting 4 processes
...
Run status group 0 (all jobs):
WRITE: bw=185MiB/s (194MB/s), 45.1MiB/s-46.7MiB/s (47.3MB/s-49.0MB/s), io=6091MiB (6387MB), run=32957-33006msec
Disk stats (read/write):
md0: ios=0/13434, merge=0/0, ticks=0/0, in_queue=0, util=0.00%, aggrios=0/6139, aggrmerge=0/578, aggrticks=0/15427600, aggrin_queue=15407792, aggrutil=99.45%
sde: ios=0/6005, merge=0/573, ticks=0/14475608, in_queue=14455992, util=97.89%
sdc: ios=0/6273, merge=0/583, ticks=0/16379592, in_queue=16359592, util=99.45%
And there you have it!!! We reached basically the same bandwidth that we could have accomplished on a P30 disk with 2 P15 disks using Software RAID (aka. mdadm) on Linux. In this simple little example we are able to save around 45% on our monthly storage bill by using Software RAID so that we didn’t have to overprovision disk to get the throughput we needed!!
Hope this helps. Good Luck.