Imagine being lost on a deserted island with no hope of being discovered with only a volleyball named Wilson to keep you company. There’s a reason pirates used marooning as a form of torture. It’s a miserable existence (if you can call it that) that usually doesn’t end so well. But yet that’s what becomes of most corporate knowledge. It’s left on various file servers and websites across the enterprise with little hope of discovery or rescue (aka. reuse).
In my last post entitled Strategic Reuse Process, we looked at an overall framework for analyzing how information flows through an organization and the hurdles encountered on its way to reuse. But how does an artifact go from Publication to Discovery? In this post I want to dig a little deeper and discuss the first hurdle on our way to reuse, Findability.
find-a-bil-ity n
a. The quality of begin locatable or navigable
b. The degree to which a particular object is easy to discover or locate.
c. The degree to which a system or environment supports navigation and retrieval
Peter Morville from Ambient Findability
All of the definitions above work equally well for what I am going to discuss in this post, mainly how can we describe the factors that influence the findability of information assets within the context of an enterprise.
Since we already have a working definition of findability let’s turn our attention to building a classification system to help us sort out some of the things that impact findability. I believe that findability has two dimensions (at least) that effect our ability to locate information. First is the degree of sharing that an object experiences and secondly is the external data associated with it over time. The degree of sharing is quite self-explanatory so let’s look next at what we mean by external data or what I’m calling applied semantics.
Applied Semantics
Applied Semantics deals with the relationship between various signs and symbols and what can be inferred from them related to the actual artifact they represent (whew!). Now that that nasty bit is out of the way what does it mean. In this case I believe that the quality and quantity of external meta data that describes the original publication produces a better chance of discovery which leads to a possibility for reuse.
There are many many bits of external data that can point to an artifact and I have only just scratched the surface by defining the following five classifications:
Unclassified
This represents information that has essentially little or no external classifications applied to it. Random documents strewn across a file system with only the author’s memory or luck as the only means for discovery are a good example. This represents the vast majority of knowledge in the enterprise.
Cataloged
Here there has been at least some attempt made to establish external data related to an artifact. It could be as simple as a document filing system or as elaborate as a fixed hierarchy of topics in which documents can exist. The internals of the publication may not be readily apparent but you have some idea about what it contains from the category in which it was cataloged.
Indexed
This is where search engines come in. They can pick apart a document and index its internals and provide an external reference to it based on the content of the document. In theory this should work great however in practice this often fails to turn up anything of significant benefit without other external data to use in conjunction with the artifact’s content. For instance Google relies on the number of links that point to a specific page as well as the page’s content for its PageRank algorithm.
User Applied Metadata
These are user generated data points that impart meaning on an existing publication. They can represent tags, ISDN numbers, author name, comments, etc. Each of these provides invaluable information that helps consumers find and use content from providers.
Solution Patterns
This represents a usage context for a particular artifact. Some patterns of usage will be discernible from the User Applied Metadata but Solution Patterns formalize this into a language that describes when and how artifacts can be applied and under what conditions they succeed and fail in usage.
Findability Categories
Now that we have a vocabulary that helps us understand the nuances of findability classification let’s apply them to a matrix so that we can categorize artifact findability.
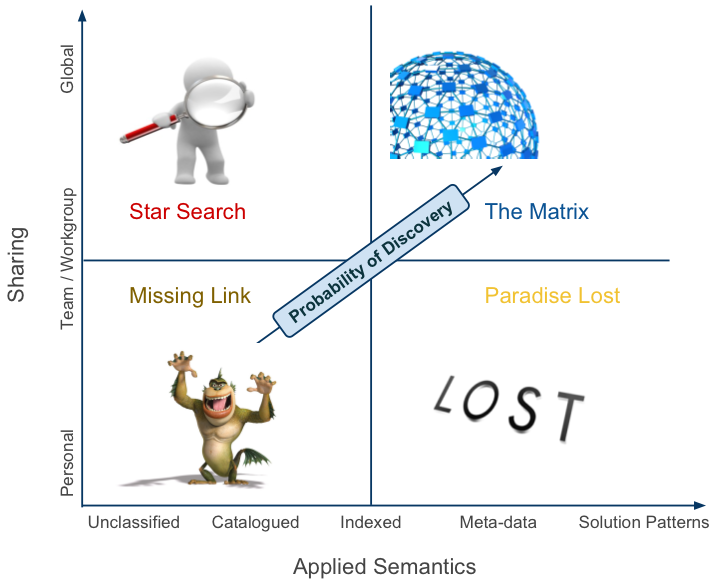
Missing Link
This is where most information and knowledge lives within an enterprise. Its focus is on the individual and small teams where communication and knowledge exchange is easiest. Examples that typify this category are personal file repositories, file shares, email inboxes, and in our developer focused example Subversion repos. Vast amounts of corporate knowledge are stored herein but due to the lack of associated external attributes and sharing this is often as far as this knowledge ever gets. Findability in this category is very low given that the information’s very existence is only known to a few individuals.
Paradise Lost
I gave this category the name Paradise Lost because that seems to be to be just what it is… a paradise of knowledge lost because the sharing attribute is so low. This is where those ultra productive teams and individuals live who have developed systems to find and share knowledge and experiences but only with small groups who happen to have knowledge of the knowledge base’s existence. Having worked in large companies for many years I can attest to the fact that some groups do an outstanding job of building knowledge bases that are tremendous assets and include features like tagging systems and user defined meta-data that help the lucky few drill into a wealth of information quickly. However the usefulness of this is limited because few people know about it or the process for using it. Such a shame.
Star Search
Besides the Missing Link this may be the most common category of Findability in the enterprise. This category represents all those well intentioned projects that seek to develop a corporate knowledge base by implementing a technology solution (aka. search). Search may seem like a great idea but at its core search is a technology solution that lacks context for relevance. Even Google realized that when they created the PageRank algorithm that combined basic search functionality with the popularity of the artifact for added relevance.
The Matrix
The Matrix (sorry for the name but I couldn’t come up with anything better at the moment) is the best of both worlds. It has a high degree of sharing combined with user generated meta-data and topped off with usage semantics that help organizations unlock the hidden knowledge within their corridors. This is where communities add tremendous value in helping to detect and apply metadata to publication artifacts.
What About Communities?
If there is one thing we haven’t really discussed in this post it’s the topic of communities and their relevance to findability. Communities exist so that its members can pursue a shared goal or interest. In this context communities are invaluable in their ability to find and disseminate relevant knowledge to others in the community. Active communities can and do enhance the findability of topical artifacts, and given the right tools, and provide invaluable metadata to help establish the relevancy of corporate knowledge to specific situations. In a word they are “priceless”.
So Where Are You?
I’m curious to get your feedback on whether or not you think this framework is on or off track in helping us understand findability within an enterprise. This is one of those areas in technology discussions where opinions are like … (oops better not go there). Everyone seems to have some theory on information management and how knowledge gets created and disseminated but I’d like to hear your practical examples of how you increased the Findability of assets in your company.